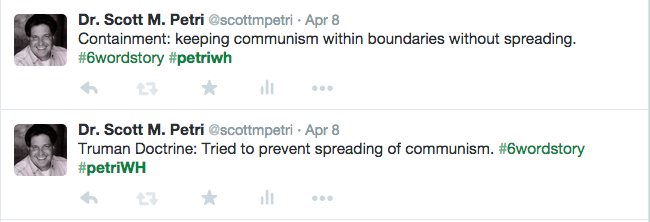
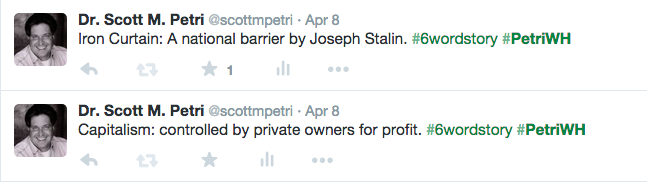
What should be remembered in Soviet textbooks? Describe three achievements that should be included in Soviet textbooks. Support your reasoning with evidence from the documents: (A) Geographic Expansion; (B) Socio-Economic Accomplishments; (C) Great Terror; (D) Political Repression; (E) Military Strength; (F) Space Achievements; (G) Olympic Victories; and (H) Ballet & Cultural Achievements.
Thesis Statement Planning
Soviet textbooks should include: ____________, _____________, and _______________.
In 69 years as a country, the Soviet Union accomplished many great things, _________, _________, and _________; should be included in their textbooks to remember this time in history.
_________, ___________, and _____________ show that communism was capable of producing greatness, this paper will argue that the Soviet Union’s Cold War accomplishments should be included in their textbooks.
Outline
- Intro
- Background on the Cold War (czar, Bolshevik, capitalism, socialism, communism, Cold War, Stalin, Krushchev, Gorbachev, Sputnik, republics, satellites, and Bolshoi)
- Definition of terms
- Thesis statement
- MEAL paragraph – Accomplishment # 1
- M – Main Idea: Topic Sentence
- E – Evidence: Proof Found in Primary Source/Book/Research
- A – Analysis: How The Evidence Proves the Main Idea
- L – Link: How a Paragraph Fits in to what the paper is trying to prove.
- MEAL paragraph – Accomplishment # 2
- M – Main Idea: Topic Sentence
- E – Evidence: Proof Found in Primary Source/Book/Research
- A – Analysis: How The Evidence Proves the Main Idea
- L – Link: How a Paragraph Fits in to what the paper is trying to prove.
- MEAL paragraph – Accomplishment # 3
- M – Main Idea: Topic Sentence
- E – Evidence: Proof Found in Primary Source/Book/Research
- A – Analysis: How The Evidence Proves the Main Idea
- L – Link: How a Paragraph Fits in to what the paper is trying to prove.
- Conclusion
- Summarize rationale – Accomplishments 1, 2 & 3 show…
- Recap evidence
- Restate thesis
In-Text vs. Parenthetical Citations
Document A shows the incredible size of the Soviet Union and its satellite countries. This suggests that …
Poland was an East European satellite country of the Soviet Union (Document A).
Evidence-based Sentence Starters
Based on this evidence, it appears that _____________________.
This quote suggests that ______________________.
When viewing the map, it is evident that _____________.
This source reveals how US policy makers thought about ___________________.
This timeline illustrates how ____________________________.
This passage provides some insight into the nature of __________________________.