Rise of The Robo-Readers
July 13 @ 4pm PST/7pm EST #sschat
co-mods: @scottmpetri & @DavidSalmanson
A primer on auto essay scoring
https://historyrewriter.com/2015/07/03/role-of-robo-readers/
Q1 What is your definition of AES, robo-reading, or robo-grading? #sschat
Q2 What is greatest hope and/or your worst fear about technology-assisted grading? #sschat
Q3 When is it ok for a computer to assign grades on student work? #sschat
Q4 How can classroom teachers test & evaluate a robograder without disrupting learning? #sschat
Q5 What would parents think if Ts required Ss to use robo-graders before submitting work? #sschat
Q6 What would school admins say if you used a robograder in your classes? #sschat
Q7 How would you use a robograder in your History-Social Science class?
Q8 How could robo-readers help teachers gamify the art and process of writing?
Shameless plug: https://www.canvas.net/browse/ncss/courses/improving-historical-writing has a module on writing feedback & AES. Course is free and open til Sept. 22. #sschat
Teaser Tweets (to promote the chat after Monday – 7/6).
Are robo-graders the future of assessment or worse than useless? http://wp.me/4SfVS #sschat
Robo-readers are called Automated Essay Scorers (AES) in education research. http://wp.me/4SfVS #sschat
In one study, Ss using a robo-reader wrote 3X as many words as Ss not using the RR. http://wp.me/4SfVS #sschat
Robo-readers produce a change in Ss behavior from never revising to 100% revising. http://wp.me/4SfVS #sschat
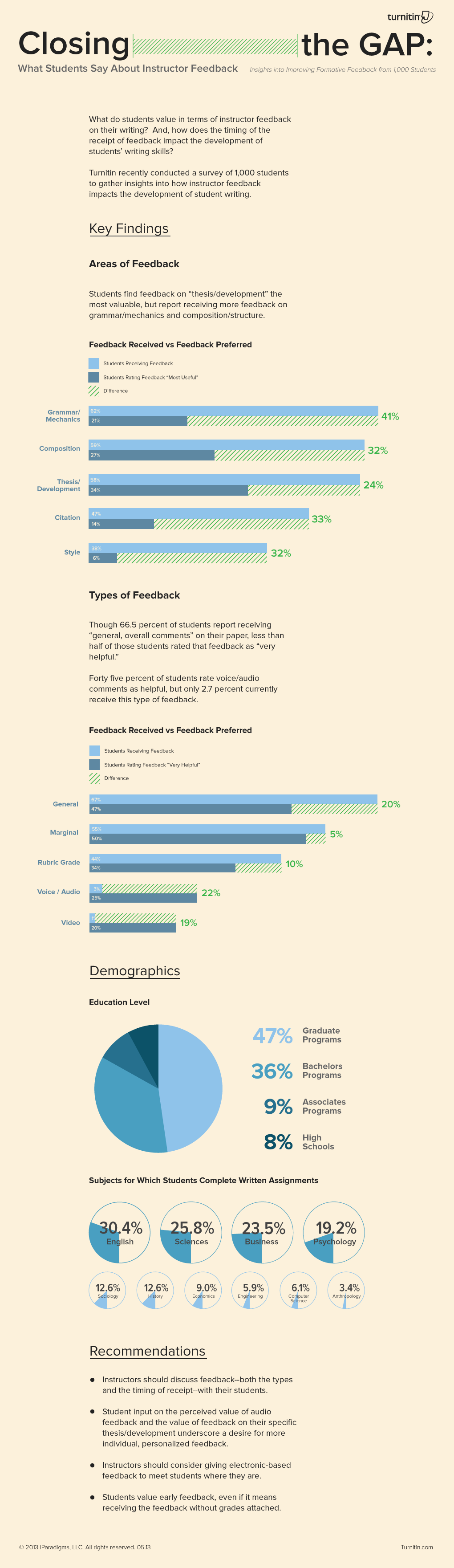
Criticism from a human instructor has a negative effect on students’ attitudes about revisions. http://wp.me/4SfVS #sschat
Comments from the robo-reader produced overwhelmingly positive feelings for student writers. http://wp.me/4SfVS #sschat
Computer feedback stimulates reflectiveness in students, something instructors don’t always do. http://wp.me/4SfVS #sschat
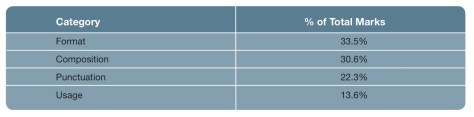
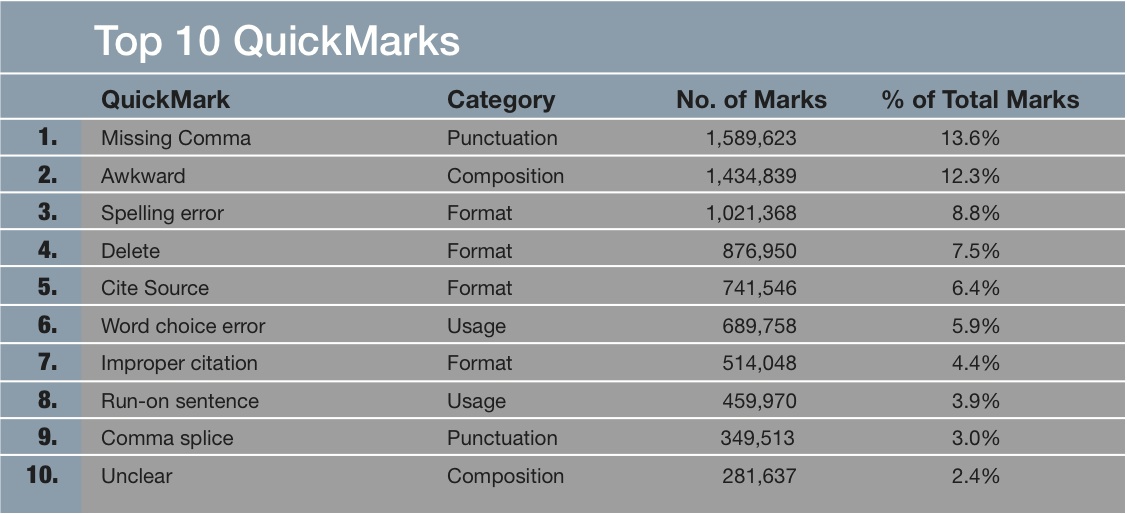
Robo-graders are able to match human scores simply by over-valuing length compared to human readers. http://wp.me/4SfVS #sschat
None of the major testing companies allow open-ended demonstrations of their robo-graders http://wp.me/4SfVS #sschat
Toasters sold at Walmart have more gov. oversight than robo-readers grading high stakes tests. http://wp.me/4SfVS #sschat
What is the difference between a robo-reader & a robo-grader? http://wp.me/4SfVS #sschat
To join the video-chat follow @ImpHRW, sign into www.Nurph.com. Enter the #ImpHRW channel. Note you will still need to enter #sschat to your tweets.
Resources
http://elearningindustry.com/top-10-free-plagiarism-detection-tools-for-teachers
http://hechingerreport.org/content/robo-readers-arent-good-human-readers-theyre-better_17021/
Promo Video for a forthcoming Turnitin.com product
https://www.youtube.com/watch?v=aMiB4TApZa8
A longer paper by Shermis & Hamner
www.scoreright.org/NCME_2012_Paper3_29_12.pdf
Perelman’s full-length critique of Shermis & Hamner
http://www.journalofwritingassessment.org/article.php?article=69
If you are really a hard-core stats & edu-research nerd
http://www.journalofwritingassessment.org/article.php?article=65
https://www.ets.org/research/policy_research_reports/publications/periodical/2013/jpdd
http://eric.ed.gov/?q=source%3a%22Applied+Measurement+in+Education%22&id=EJ1056804
National Council of Teachers of English Statement
http://www.ncte.org/positions/statements/machine_scoring
For Further Research
Williamson, D. M., Xi, X., & Breyer, F. J. (2012). A framework for evaluation and use of automated scoring. Educational Measurement: Issues and Practice, 31(1), 2-13.